ChronoMath, une chronologie des MATHÉMATIQUES
ą l'usage des professeurs de mathématiques, des étudiants et des élčves des lycées & collčges
|
» Programme en ligne de calcul des paramčtres d'un couple (X,Y) | ∗∗∗ exercice #5 | voir aussi : #1 , #2 , #3 , #4 Statistique élémentaire ą 1 dimension | Régression par la méthode des moindres carrés |
Cette page suppose connus le vocabulaire et les résultats fondamentaux de la statistique élémentaire enseignée au collčge et au lycée. Il s'agit ici de préciser le vocabulaire utilisé dans l'étude d'une population statistique dont deux caractčres quantitatifs X et Y sont récoltés simultanément sous la forme de couples de données (xi, yj). On parle de couple statistique (X,Y). L'objectif principal étant l'estimation de la corrélation et de la dépendance, aux sens usuels et statistiques de ces termes, pouvant exister entre ces caractčres. Il est équivalent de parler de statistique double ou de statistique ą deux dimensions.
➔ Il faut distinguer ce cas de celui, plus élémentaire, de la donnée de deux séries ą 1 dimension X = (xi, mi) et Y = (yi, ni), i = 1,2, ...n, oł X et Y sont récoltées et étudiées séparément, mi et ni désignant respectivement les effectifs des valeurs observées xi et yi. L'objectif étant, in fine, d'établir une corrélation entre X et Y, en particulier une relation fonctionnelle de type Y = f(X). Voyez par exemple cet exercice ou celui-ci ou encore celui-lą.
Dans le cas présent, l'objectif est le mźme mais, comme il a été dit supra, les données récoltées sont des triplets de valeurs (xi, yj,ni,j ), les effectifs observés étant ceux du couple (xi, yj). On résume les données au moyen d'un tableau ą double entrée en X et Y.
Par exemple : (» exercice)
Ci-dessous, le couple (40,7) correspondant ą X = 40 et Y = 7, a
été observé 16 fois. On peut déduire de ce tableau que X = 40 a été rencontré 42
fois (5 + 16 + 12 + 9) au cours de cette étude statistique : ą partir de l'étude
d'un couple statistique, on peut déduire les distributions de X et de Y. Comme
nous allons le voir, on parle de distribution marginale.
| xi \ yj | 6 | 7 | 8 | 9 |
| 30 | 2 | 4 | 9 | 8 |
| 40 | 5 | 16 | 12 | 9 |
| 50 | 15 | 10 | 6 | 4 |
➔ Dans cette page, on fera souvent le lien avec le contexte probabiliste oł X et Y représenteraient alors des variables aléatoires discrčtes définies sur un mźme espace probabilisé. On remarquera qu'il suffit pour cela de remplacer simplement fréquence par probabilité.
Relativement ą la statistique élémentaire ą 1 dimension, on remarquera ci-dessous de nombreuses redondances. Le vocabulaire propre aux couples statistiques concerne :
les effectifs marginaux, les fréquences marginales;
les fréquences conditionnelles, la notion d'indépendance statistique;
la covariance, la corrélation.
Nuage de points, Regroupement en classes, Effectifs et fréquences :
♦ Dans ce cas de deux variables, deux caractčres X et Y d'une population statistique de N individus (effectif total) sont observés. On suppose avoir relevé deux séries d'observations, m valeurs (xi) 1≤ i ≤ m de X et p valeurs (yj) 1≤ j ≤ p de Y. On parle de nuage de points que l'on peut représenter dans un repčre orthogonal : points Mi,j de coordonnées (xi, yj).
En toute généralité, les index i et j n'ont pas la mźme amplitude de variation : m ≠ p dans la mesure oł les valeurs d'un caractčre peuvent źtre plus fluctuantes que l'autre au sein de la population.
Pour des séries ą fort effectif, tout comme dans le cas des statistiques ą 1 dimension et en particulier concernant des caractčres pouvant varier continument (pouvant prendre a priori toute valeur dans un intervalle donné), les valeurs recueillies sont souvent triées et regroupées en un certain nombre de classes. Les xi et yj sont alors les centres des classes.
Séries classées : »
On appelle effectif (partiel) d'un couple (xi, yj), le nombre ni,j d'observations simultanées de xi et yj chez un individu. On a :
» Les auteurs spécialisés en la matičre utilisent ou non le qualificatif partiel dans la définition ci-dessus. L'option ici choisie est de l'omettre dans la mesure oł tout effectif non qualifié de total sera, par défaut, partiel.
Diagramme des effectifs :
Le diagramme des effectifs ą 2 dimensions est la représentation d'une fonction du type (x,y) →z∈N. Il s'agit donc d'une représentation 3D oł les effectifs sont portés en cote (diagramme de droite ci-dessous). Grāce aux ordinateurs et ą l'usage des tableurs, on peut facilement obtenir des représentations trčs sophistiquées. Le diagramme de gauche exprime le diagramme des effectifs en statistique ą 1 dimension, du type x→y.

On appelle fréquence d'un couple (xi, yj), le nombre fi,j = ni,j /N, quotient de son effectif par l'effectif total de la série double.
♦ Effectifs marginaux :
» Les auteurs spécialisés en la matičre utilisent ou non le qualificatif partiel dans les définitions ci-dessus. L'option ici choisie est de l'omettre dans la mesure oł tout effectif non qualifié de total sera, par défaut, partiel.
L'ensemble des couples (xi, yj,, ni,j) i = 1,2,...,k est qualifié de distribution d'effectifs. On la résume dans un tableau ą double entrée (en bleu) en faisant apparaītre les effectifs marginaux (en vert). On voit lą le pourquoi de l'appellation marginal(e) : les effectifs marginaux et fréquences marginales (en jaune, définies ci-aprčs) apparaissent en marge du tableau.
On remarque que :

♦ Fréquences/Probabilités marginales :
En marge du tableau ci-dessus (en jaune), sont indiquées les fréquences marginales (probabilités marginales dans le cas aléatoire) des données en X et Y :
fxi indique la fréquence observée d'une valeur xi de X indépendamment des valeurs observées de Y :

fyj indique la fréquence observée d'une valeur yj de Y indépendamment des valeurs observées de X :

La somme sur i et j des fréquences fi,j = ni,j /N des couples (xi, yj) est égale ą 1 comme on doit s'y attendre. Elle n'est autre que les sommes des fréquences marginales tant en i que en j, ce qui permet de vérifier les calculs.
 dans
le cas d'un couple aléatoire, fxi est la
probabilité de réalisation de l'événement [X = xi] : il
s'agit de la loi de probabilité de X. Remarque
analogue concernant les fyj .
dans
le cas d'un couple aléatoire, fxi est la
probabilité de réalisation de l'événement [X = xi] : il
s'agit de la loi de probabilité de X. Remarque
analogue concernant les fyj .
♦ Fréquences conditionnelles :
la fréquence conditionnelle de xi relativement ą yj (on dit aussi sachant yj) :
![]()
la fréquence conditionnelle de yj relativement ą xi (on dit aussi sachant xi) :
![]()
On constate que fyj/xi , fréquence conditionnelle de yj sachant xi , peut s'écrire ni,j /N ÷ ni,•/N , c'est ą dire comme quotient de la fréquence du couple (xi, yj) par la fréquence marginale de xi. On en déduit :
fi,j = fxi × fyj/xi
Autrement dit :
La fréquence d'un couple (xi, yj) est le produit de la fréquence marginale de xi par la fréquence conditionnelle de yj sachant xi.
De mźme :
fi,j = fyj × fxi/yj
La fréquence d'un couple (xi, yj) est le produit de la fréquence marginale de yj par la fréquence conditionnelle de xi sachant yj.
en termes de probabilités conditionnelles, fi,j
s'interprčte comme la probabilité de l'événement (X = xi )∩(Y
= yj) et fxi comme la probabilité de l'événement (X = xi),
conduisant ą prob[(X = xi )∩(Y
= yj)] = prob(X = xi) × prob[(Y
= yj)/(X = xi)] :
prob(A∩B) = prob(A) × prob(B/A) = prob(B) × prob(A/B)
♦ Indépendance statistique de deux caractčres X et Y :
Les caractčres X et Y sont dits indépendants lorsque pour tout i et j, on a : fxi/yj = fxi et fyj/xi = fyj.
C'est dire que :
les fréquences des valeurs xi de X ne dépendent pas
des valeurs yj de Y et de mźme
les fréquences des valeurs yj de Y ne dépendent pas des valeurs xi
de X.
La condition d'indépendance peut aussi s'écrire : fi,j = fxi × fyj, c'est ą dire :
pour tout i et j : N × ni,j = ni,• × n•,j
en termes de probabilités, p (A∩B)
= p(A) × p(B),
p(A/B) = p(A), p(B/A) = p(B).
Théorčme de Bayes et indépendance en probabilités : »
♦ Valeurs moyennes (espérance mathématique) :
La valeur moyenne d'une série statistique X (reps. Y) est la moyenne X (resp. Y) de ses valeurs pondérées par leurs effectifs marginaux :
 (m1)
(m1)
N étant un coefficient indépendant de i, on peut le placer en division de ni,• (resp. n•,j) permettant d'introduire les fréquences marginales de xi (resp. yj) :
 (m2)
(m2)
en termes
probabilistes, pour une variable aléatoire X dont les valeurs xi
sont prises avec la probabilité pi, = Prob[x = xi] sa
valeur moyenne (espérance mathématique), notée E(X), est pondérée par les probabilités
: E(X) = Σpixi
: la probabilité pi d'apparition de la valeur xi
joue dans ce cas le rōle de la fréquence d'apparition de cette valeur.
On peut aussi exprimer X et Y au moyen des fréquences fi,j = ni,j /N des couples (xi, yj) en exprimant ni,• (resp. n•,j) par leur expression en fonction des ni,j :
 (m3)
(m3)
C'est ą dire :
 (m4)
(m4)
∗∗∗
a) Justifier que si une série X = (xi) est
constante : xi = k pour tout i, alors E(X) = k.
b) Vérifier que l'espérance mathématique est une forme linéaire : E(X + Y) =
E(X) + E(Y), E(kX) = k.E(X)
Propriété 0 :
On vérifiera facilement que :
aX + b = aX + b ; en termes d'espérance mathématique E(aX + b) =aE(X) + b.
Propriété 1 :
Dans le cas oł les séries X et Y sont indépendantes, on a : E(X × Y) = E(X) × E(Y)
Preuve : selon l'hypothčse, on a (indépendance) fi,j = fxi × fyj. En utilisant (m3) la somme sur i,j, c'est ą dire E(X × Y) se décompose alors en le produit des sommes Σ fxi × xi et Σ fyj × yj : c'est ą dire E(X)E(Y).
♦ Variance :
La variance V d'une série statistique ou d'une variable aléatoire X est la moyenne des carrés des écarts de ses valeurs par rapport ą sa moyenne :

ou bien, au moyen des fréquences marginales des xi et (resp. yj) :
La formule de Huygens-Koenig est souvent d'une grande utilité dans les calculs :
V(X) = X2 - (X)2 soit, en termes probabilistes : V(X) = E(X2) - [E(X)]2 (m5)
Propriété 2 :
Dans le cas oł les séries ou les variables aléatoires X et Y sont indépendantes, on a : V(X+Y) = V(X) + V(Y)
Preuve : utiliser la formule ci-dessus en développant les carrés et utiliser la propriété 1. » m6
Propriété 3 :
En en utilisant
la formule de Koenig, on montrera facilement que pour
tout réel a et b :
V(aX + b) = a2V(X)
♦ Écart-type ou déviation standard :
On utilise les carrés des écarts et non les écarts eux-mźmes afin d'éviter une correction fallacieuse entre des écarts positifs et négatifs. L'usage de l'écart moyen arithmétique est trčs rarement utilisé car peu opérationnel de par les valeurs absolues et son absence de propriétés additives en présence de variables indépendantes.
L'écart-type ou l'écart quadratique moyen ou encore la déviation standard (» Pearson) d'une série ou variable aléatoire X est la racine carrée de la variance, il est un marqueur de la dispersion "autour" de sa moyenne :

Propriété 4 :
En conséquence de la propriété 3 et 2 ci-dessus, on a :
♦ Covariance :
La covariance cov(X,Y) des séries ou variables aléatoires X et Y est la moyenne des produits (X - X)(Y - Y) des écarts ą leur moyenne. On peut en donner l'expression suivante (» m3), avec fi,j = ni,j /N :

fi,j = ni,j
/N = Prob[(X,Y) = (xi, yj)] = Prob[(X = xi)
∩(Y = yj)]
Autre formule pratique :
On a fi,j × (xi - X)(yj - Y) = fi,j × xiyj - Yfi,j × xi - Xfi,j × yj + X × Y × fi,j. En sommant ces expressions, double sommation dont des éléments sont indépendants de i ou bien de j, on constate que la covariance de X et Y peut s'écrire (» opérateur de sommation), en remarquant que la somme des fréquences fi,j des couples (xi, yj) est égale ą 1 :


Ce que l'on peut aussi écrire :
en
termes de probabilités et d'espérance mathématique :
cov(X,Y) = E(XY) - E(X)E(Y) : espérance du produit diminué du produit de espérances
En développant cov(X,Y) = XY - X Y, on vérifiera facilement cette propriété de la covariance :
Propriété 5 :
cov(aX + b,αY + β) = aα × cov(X,Y) (p5)
Noter que, compte tenu de (p1), la covariance de deux séries indépendantes X et Y est nulle.
On montrera d'ailleurs facilement au moyen de la formule (m5) que l'on a dans tous les cas :
V(X) + V(Y) = V(X) + V(Y) + 2cov(X,Y) (m6)
Voir aussi une conséquence de (p7) selon laquelle :
♦ Coefficient de corrélation :
Il s'agit du nombre r = corr(X,Y) défini par :

Cet important paramčtre statistique est étudié ą la page consacrée ą Karl Pearson. Énonēons ici deux importantes propriétés :
Propriété 6 :
Le coefficient de corrélation est invariant par transformation affine (appliquer p4 et p5) :
corr(aX + b,αY + β) = corr(X,Y)
En particulier, il n'est pas modifié si les lois sont centrées et réduites par les transformations :
Propriété 7 :
Le coefficient de corrélation vérifie la double inégalité : -1 ≤ r ≤ 1, ou si l'on préfčre : | r | ≤ 1.
Preuve : selon p6, on peut se placer dans le cas centré mX = mY = 0. On a r2 = cov(X,Y)/[V(X)V(Y)] = E(XY)2/[V(X)V(Y)] = E(XY)2/[E(X2)E(Y2)]. Considérons maintenant E(X + λY)2. Ce nombre est non négatif pour tout λ réel. Développons : λ2E(Y2) + 2λE(XY) + E(X2) ≥ 0 quel que soit λ. Vu que E(Y2) > 0 (sinon Y est nulle), le trinōme en λ sera positif quel que soit λ si son discriminant réduit E(XY)2 - E(X2)E(Y2) est négatif (ou nul). Par suite E(XY)2 ≤ E(X2)E(Y2), ce qui montre que l'on a r2 ≤ 1, donc -1 ≤ r ≤ 1.
Ce calcul montre une nouvelle propriété de la covariance :
cov(X,Y) ≤ σ(X)σ(X)
Lien avec le cosinus d'un angle dans un espace vectoriel normé de dimension finie : »
♦ Incidence d'une transformation affine sur les paramčtres définis ci-dessus :
Dans les calculs statistiques (resp. probabilistes), il est courant de "recentrer" un caractčre (resp. une variable aléatoire) par rapport ą sa moyenne (resp. espérance mathématique) et/ou de ramener ses valeurs dans un intervalle voulu. Pour cela, une transformation de type affine X → aX + b est utilisée.
C'est le cas, par exemple, dans le cas de la loi Laplace-Gauss que l'on ramčne ą la loi dite normale de moyenne nulle, d'écart-type 1 (loi centrée réduite) par la transformation X→ (X - m)/σ oł m est sa moyenne et σ son écart-type, permettant de dresser des tables de distribution de probabilités.
On résume ici les propriétés rencontrées tout au long de cette page :
aX + b = aX + b (linéarité); en termes d'espérance mathématique E(aX + b) =aE(X) + b.
V(aX + b) = a2V(X)
σ(aX + b) = aσ(X)
cov(aX + b,αY + β) = aαcov(X,Y)
∗∗∗
Exemple d'application
Exercice (modifié) inspiré de Statistique dans l'entreprise, C. Garnier et B. Guilbaud,
Éd. Foucher, 1979.
Dans cet exercice purement didactique oł la correction est faite pas ą pas, on fait appel aux notions et résultats présentés dans cette page. La seule difficulté réside dans la prudence ą observer du fait que les variables sont pondérées. Il faut donc utiliser ą bon escient les formules appropriées.
On a relevé sur 100 véhicules, la durée des pneumatiques (exprimée en milliers de km) et la puissance fiscale. En notant X = (xi) la série des durées des pneumatiques et Y = (yi) la série des puissances fiscales, on a établi le tableau suivant :
| xi \ yj | 6 | 7 | 8 | 9 |
| 30 | 2 | 4 | 9 | 8 |
| 40 | 5 | 16 | 12 | 9 |
| 50 | 15 | 10 | 6 | 4 |
oOo
1°/ Calculer les valeurs moyennes (espérances mathématiques) de X, Y et XY.
| xi\ yj | 6 | 7 | 8 | 9 | Eff. margi. ni,• |
ni,•xi |
| 30 | 2 | 4 | 9 | 8 | 23 | 690 |
| 40 | 5 | 16 | 12 | 9 | 42 | 1680 |
| 50 | 15 | 10 | 6 | 4 | 35 | 1750 |
| Eff. margi n•,j |
22 | 30 | 27 | 21 | 100 |
Total = 4120 |
| n•,jyj | 132 | 210 | 216 | 189 |
Total = 747 |
Selon le tableau, on a X = 4120/100 = 41,2, Y = 747/100 = 7,47.
Concernant l'espérance de XY, l'usure des pneumatiques, on s'en doute, est liée ą la puissance fiscale : on ne peut pas appliquer la formule de l'espérance d'un produit E(XY) = E(X)E(Y) dans le cas de l'indépendance statistique. Preuve en est que l'on n'a pas la condition N x ni,j = ni,• x n•,j , loin s'en faut...
On passe donc au calcul de la somme des produits xiyj par leurs effectifs ni,j et on divise par N : XY = 30480/100 = 304,8.
| xiyj | 180 | 210 | 240 | 270 | 240 | 280 | 320 | 360 | 300 | 350 | 400 | 450 | Σ |
| ni,j | 2 | 4 | 9 | 8 | 5 | 16 | 12 | 9 | 15 | 10 | 6 | 4 | 100 |
| xiyj.ni,j | 360 | 840 | 2160 | 2160 | 1200 | 4480 | 3840 | 3240 | 4500 | 3500 | 2400 | 1800 | 30480 |
2°/ Déduire de 1° la valeur de cov(X,Y)
On déduit de 1° que cov(X,Y) = XY - X Y = 304,8 - 41,2 x 7,47 = -2,964.
3°/ Calculer les variances et les écarts-types de X et de Y.
Pour ces calculs, on utilise la trčs pratique formule de Huygens-Koenig (» m5) : V(X) = E(X2) - [E(X)]2
|
|
36 | 49 | 64 | 81 | Eff. margi. ni,• |
ni,•xi2 |
| 900 | 2 | 4 | 9 | 8 | 23 | 20700 |
| 1600 | 5 | 16 | 12 | 9 | 42 | 67200 |
| 2500 | 15 | 10 | 6 | 4 | 35 | 87500 |
| Eff. margi n•,j |
22 | 30 | 27 | 21 | 100 |
Total = 175400 |
| n•,jyj2 | 792 | 1470 | 1728 | 1701 |
Total = 5691 |
Selon le tableau, on a :
E(X2) = 175400/100 = 1754. Donc V(X) = 1754 - 41,22 = 56,56; d'oł σ(X) ≅ 7,52.
E(Y2) = 5691/100 = 56,91. Donc V(Y) = 56,91 - 7,472 ≅ 1,11; d'oł σ(Y) = 1,053.
4°/ Existe-t-il une corrélation pertinente entre les deux caractčres observés ?
Le coefficient de corrélation est r = cov(X,Y)/[σ(X)σ(Y)] = -2,964/(7,52 × 1,053) = - 0,374 : | r | = 0,374 < 0,5 n'est pas "proche" de 1. Une corrélation linéaire est donc ici ą rejeter. » Pearson
➔ Pour en savoir plus :
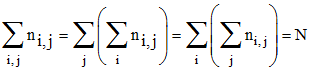 »
»





